

"Retrieval-Augmented Generation for Large Language Models: A Survey" - A Read Through
Part 1

In this post I will be going through the paper titled “Retrieval-Augmented Generation for Large Language Models: A Survey” by Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, and Haofen Wang from the Shanghai Research Institute for Intellegent Autonomous Systems [1].
Link to paper if you want to follow along.
My goal is to make a series of posts as I read these papers myself, that walks through the material and is an easy and quick way to read for others who are interested. I will highlight the things that I found interesting or important and try to cover any needed background within a reasonable framework.
Anywhere you see a block quote is an excerpt from the paper in the section given in the heading:
Example of a block quote
I will also try to stay in the same order of the paper.
Let’s get started!
Paper Abstract
In general this paper is an overview about the most current strategies and insights into the Retrieval Augmented Generation (RAG) architecture for LLMs. If you aren’t familiar with this yet, the basic idea is that LLMs are good are having base knowledge, but since they are basically just really good next work predictors, it is entirely possible they make up facts while generating text for the user… this is called hallucinating. In order to stop this, we need to supply the LLM with information that is current and correct, and we can do this by searching for relevant information in a database to serve to the model with the user query - hence the retrieval augment to the generated text.
RAG effectively combines the parameterized knowledge of LLMs with non-parameterized external knowledge bases, making it one of the most important methods for implementing large language models.
Note: parameterized knowledge just means the knowledge that was baked into the model by training or fine-tuning.
This paper outlines the development paradigms of RAG in the era of LLMs, summarizing three paradigms: Naive RAG, Advanced RAG, and Modular RAG. It then provides a summary and organization of the three main components of RAG: retriever, generator, and augmentation methods, along with key technologies in each component. Furthermore, it discusses how to evaluate the effectiveness of RAG models, introducing two evaluation methods for RAG, emphasizing key metrics and abilities for evaluation, and presenting the latest automatic evaluation framework.
As we can see, the paper is going to go deep into the components of RAG, the strategies within RAG, and how to measure that it is working correctly.
Note: In my experience, one of the hardest parts of RAG based architectures in getting the correct response back from your search. It can be incredibly difficult depending on the use case. We will come back to this in the evaluation section.
Onward.
Paper Introduction
The introduction to this paper gives a brief history of LLMs and the limitations associated.
However, large language models also exhibit numerous shortcomings. They often fabricate facts[Zhang et al., 2023b] and lack knowledge when dealing with specific domains or highly specialized queries[Kandpal et al., 2023]
This is setting up the narrative that we need to be able to include “grounded” information for the model with the query. I don’t think this is particularly interesting for this read through, so let’s skip to something a little more juicy. If you are not familiar with how neural networks work, read the introduction and it will help.
The development of RAG algorithms and models is illustrated in Fig 1. On a timeline, most of the research related to RAG emerged after 2020, with a significant turning point in December 2022 when ChatGPT was released.

We can easily see in this tree that the development of models in this space exploded after GPT-3 and even more so after ChatGPT. If you have time, some interesting algorithms/models to check out are self-RAG, GenRead, and InstructRetro.
Next!
Background
RAG vs. Fine-tuning
RAG is akin to providing a textbook to the model, allowing it to retrieve information based on specific queries. This approach is suitable for scenarios where the model needs to answer specific inquiries or address particular information retrieval tasks. However, RAG is not suitable for teaching the model to understand broad domains or learn new languages, formats, or styles.
Fine-tuning is similar to enabling students to internalize knowledge through extensive learning. This approach is useful when the model needs to replicate specific structures, styles, or formats. Fine-tuning can enhance the performance of non-fine-tuned models and make interactions more efficient.
Okay so important piece here - when do I fine-tune, and when do I RAG?
I think it can be summed up mostly by the following:
Fine-tune when you want to specialize the model. (Domain knowledge, Model “voice”, output structure expectations, etc.)
RAG when you want to ground the answers in truth. (Answer must be correct, information changes frequently, answer needs citations, too wide of a spectrum for parameterized knowledge to cover, etc.)
One other important distinction is if you dataset is massive, the resources required to train or fine-tune a model might be massive as well. With RAG, you only use the resources required to embed and search the data. This may be a large consideration, so keep it in mind.
We should also note:
RAG and fine-tuning are not mutually exclusive but can complement each other, enhancing the model’s capabilities at different levels. In certain situations, combining these two techniques can achieve optimal model performance. The entire process of optimizing with RAG and fine-tuning may require multiple iterations to achieve satisfactory results.
When they say multiple iterations to achieve good results, they mean it. In my experience this can be the most lengthy part of the project, even over data engineering / cleaning.
For quick reference, here is the table they provide for differences between the strategies:
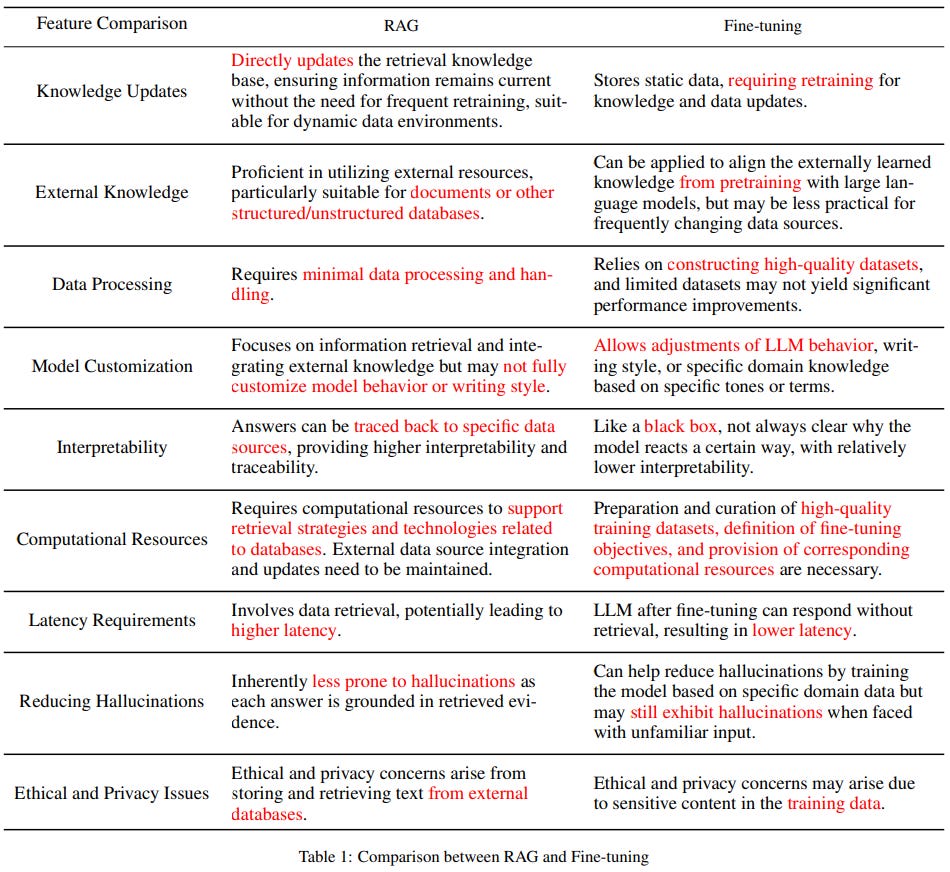
Okay, now let’s quickly take on the RAG strategies - Naive, Advanced, and Modular RAG.
I will try to keep it brief with only the important points and you can dig into the paper if more information is needed.
Naive RAG
The naive RAG involves traditional process: indexing, retrieval, and generation. Naive RAG is also summarized as a “Retrieve”-“Read” framework [Ma et al., 2023a].
Indexing - Clean and extract data into unstructured plain text, and “chunk” the data into sections that might be useful for the model to use. Then embed these chunks into vectorized format using an embedder of your choice.
Retrieval - Embed the user query with the same embedder and retrieve the most similar document according to a specified similarity metric. Some popular metrics are cosine similarity, Euclidean distance, and dot product. Each has their own advantages, and you can learn more here.
Generation - The user query is combined with the retrieved similar information to help direct the model to answer the question correctly. This can abstractly be thought of as shifting the underlying probabilities for the token prediction, such that each token that is predicted is grounded in the prior from the appended context (retrieved documents).
Regarding retrieval quality, the issues are multifaceted. The primary concern is low precision, where not all blocks within the retrieval set correlate with the query, leading to potential hallucination and mid-air drop issues. A secondary issue is low recall, which arises when not all relevant blocks are retrieved, thereby preventing the LLM from obtaining sufficient context to synthesize an answer.
Note: This is what I mentioned earlier. It is extremely hard to make sure you are getting the right supporting information for the query using a naive strategy. Even if you tell the model to “not answer the query if the information is not given”, we can’t be sure that the information wasn’t retrieved and the query answerable.
Issues:
Low recall or low precision
Out-dated information requires extra maintenance
Potential hallucinations if prompt engineering fails
Redundancy when retrieved chunks contain repeated info.
Advanced RAG
The idea with advanced RAG is to improve the pain points of naive RAG, while still having quality and useful information delivered to the prompt when sent to the LLM.
Optimizing Data Indexing
In this section the authors give a few strategies to enhance the quality of the index.
Currently, there are five main strategies employed for this purpose: increasing the granularity of indexed data, optimizing index structures, adding metadata, alignment optimization, and mixed retrieval.
Granularity - Pre-index optimization aims to enhance text standardization, consistency, and factual accuracy while ensuring contextual richness for the RAG system's performance. This involves removing irrelevant or redundant information, clarifying ambiguities, verifying facts, and continuously updating the system with real-world context and user feedback to maintain efficiency and reliability. Pretty intuitive right? Kind of like data pre-processing in the traditional ML world.
Index Structures - Optimizing the index involves adjusting chunk size, altering index paths, and incorporating graph structure information. Chunk size adjustment focuses on balancing context relevance and noise, while different indexes may be used for querying, either based on specific queries or metadata like dates. Incorporating a graph structure by transforming entities into nodes enhances accuracy and relevance, especially for complex, multi-hop queries.
Metadata - Embed metadata into the chunks that have a meaningful impact on the embedding relative to the query. We can also filter through the metadata before we retrieve as well.
Alignment - We want to make sure that the query and the retrieved documents are aligned as possible to increase the accuracy of the retrieval. We will talk about HyDE (Hypothetical documents) in a bit.
Mixed Retrieval - Basically, use different retrieval strategies like keyword search, semantic search, etc. and then combine them together! Obviously this will make the search process more robust.
Embedding
Fine-tuning - Intuitively, if the model doing your retrieval is hyper focused on your data or your domain, it should perform better. Just like with any NN, if you train on examples of what you are looking for (question / answer pairs in your dataset), the embedding model will work better. No surprise here. For enterprise:
Especially in professional domains dealing with evolving or rare terms, these customized embedding methods can improve retrieval relevance.
Dynamic Embedding - Dynamic embedding just means using models that don’t just embed a specific word to a specific vector every time. With dynamic embedding, the embedder pays attention to the context of the word to change the vector representation where needed.
Post-Retrieval
Let’s say we use all of the above strategies. We might end up with a ton of supporting documents from the retrieval process to send to the LLM, but then we have to worry about exceeding the context window and the LostInTheMiddle problem. (We will talk about this later) So how can we choose which documents to send to the LLM?
ReRank - As the authors say:
Re-ranking to relocate the most relevant information to the edges of the prompt is a straightforward idea.
You take the best answers, and you put them on the front and back of the prompt alternating so that they are as far from the middle as possible. You can end this process when you reach the context window, or just set a K value for K included documents.
Prompt Compression - Research suggests that noise in retrieved documents hinders RAG system performance, leading to post-processing techniques that focus on condensing irrelevant content and emphasizing key paragraphs. Methods like Selective Context and LLMLingua use small language models to assess content importance, while newer approaches like Recomp and Long Context address the challenges of maintaining key information in long-context scenarios through specialized compression and summarization techniques.
Layers and layers of LLM tools!
Pipeline Optimization Strategies
Hybrid search - blend different techniques with semantic search, get better results.
Recursive retrieval - Break down the query into smaller document searches, and work your way up to the bigger document to maintain semantic meanings.
Step back Prompting - encouraging LLMs to focus on general concepts rather than specific instances. For example “What physics principles are behind this question?”
Subqueries - break the query down into sub queries, answer, summarize all answers for final answer.
HyDE - Ask an LLM to answer the user query, and make the assumption that the answer might be closer in vector space to the real answer documents, so embed the answer and retrieve what is closest to it. Then you can send the retrieved documents to the LLM to answer the question with grounded truth.
Modular RAG
If you are an engineer, it might be clear to you so far that the above set of solutions are great for solving select problems. But as complexity of the problem increases, so do the gaps in the framework given. That is where modular RAG comes in. This allows us to make a robust pipeline that can dynamically handle many different cases within the same framework. This is where you want to be when making applications that are user facing or important internally.
Models
Search model - LLM generated SQL code, etc. (specific scenario models)
Memory module - Create a memory chain that the LLM can use to more finely understand and retrieve relevant context. Ideally, you can use the output of the model as memory to enhance itself within the context window. Like fine tuning without the compute :)
Extra Generation - You can think of this as a summarization step for the retrieved documents to handle any redundancy or noise.
Task Adaptable Module - Use examples of context to create task specific retrievers. For instance, if you are looking to retrieve documents about US presidents, the task module would create or retrieve a specific prompt for that task.
Alignment Module - Train an adapter module in the LLM to be rewarded for doing well in your use case. This is basically lightweight fine-tuning by squeezing in trainable layers in the overall model that are reinforced for your context.
Validation Module - Ask an LLM if it makes sense! After all, LLMs are great at seeing if the context matches once given all of the information.
The “New Pattern” section goes on to explain how one might adjust their pipeline to incorporate these strategies but I think it is repetitive for this article.
So at this point the paper has done a good job of looking at RAG wholistically. We have explored strategies that can tighten up the RAG pipeline and create a really robust way of retrieving and answering questions. Since this article is getting pretty long, I am going to do the read through of the rest in the next article.
Next time we will talk about:
Retriever specifics
Output alignment
Generator specifics
How to optimize adapting
Evaluation!
These sections are much more technical so it seems like a good place to split.
I hope this article helped read through the first half of the paper super fast, and you enjoyed the read along the way!
Thanks for reading,
Luke
Citations
[1] Gao, Y. (2023, December 18). Retrieval-Augmented Generation for Large Language Models: A survey. arXiv.org. https://arxiv.org/abs/2312.10997v1